Virtual Avatar of a TV character
The goal of this work is to learn a computational model of a person's sound and appearance, their style of speech and interactive behaviour, through automatic analysis of a video collection.
Such a system would be useful for natural-human computer interaction and could be a step towards a form of "virtual immortality". Our approach towards this goal is demonstrated by automatically learning to synthesise an avatar of a TV character, such as Joey from Friends.
Why is this difficult?
Machine learning algorithms are used to train the avatar to talk and move in the same style as a character from a TV show.
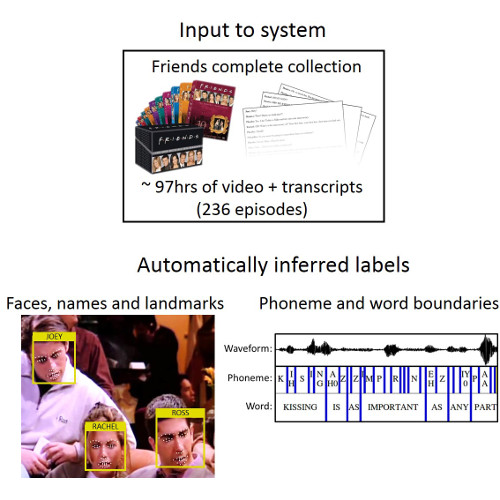
However, training labels, such as face location, face identity, mouth shape and spoken word timings of a chosen character, are required for training.
To extract these labels from a TV show, automatic inference methods were developed from state-of-the-art computer vision and speech recognition algorithms. These algorithms can be applied to all episodes of the TV show and with the help of transcripts extract this label information automatically.
Algorithms and model construction
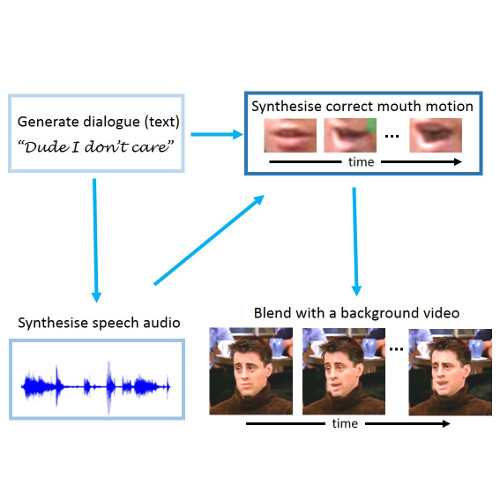
The talking avatar is driven by first generating dialogue using a deep recurrent neural network (RNN) trained from a character's transcripts.
Corresponding speech audio and mouth motion is synthesised in their style and voice. Voice and mouth synthesis is based on concatenating small audio and video snippets together from a database of collected phonemes (units of speech) and dynamic visemes (dynamic units of mouth motion).
The mouth motion is blended with a background video of the character to form the final synthesis. For more details, please see our peer-reviewed publication.
How we doin'?
In experiments the method is applied to all 236 episodes of Friends to obtain a virtual representation of Joey. The video to the left shows example audio-visual output of generated scenes with Joey saying new sentences.
The avatar is able to say new sentences by sampling them from the RNN, other example sentences are also given here.
- Yeah what is it.
- Oh ooh what do you.
- Dude i dont care what is a little him.
- I was thinking about.
- Do you need this thing.
- Yeah im sorry i wasnt feel good time.
- Then i just say i thought.
- All right now well that was a soup.
- Maybe he have to beet on it.
- Yeah what are you doing.
- Chandler im gonna get my porsche.
- How do you do it.
- Tell that but the challis girls for you.
- Oh can i like this up the cansy.
- Really maybe it was there.
- But what does this said i love.
Peer-reviewed publication
Selected press coverage
The Verge
The Guardian
The Telegraph
Digital Trends
CNET
Radio Coverage
The Ringer
ScienceNode
Software
Face detection and tracking software developed for this project can be downloaded from Github.